A tuple is an assortment of items which requested and permanent. Tuples are successions, very much like records. The contrasts among tuples and records are, the tuples can't be changed not normal for records and tuples use enclosures, though records utilize square sections. Making a tuple is pretty much as straightforward as putting diverse comma-isolated qualities. Alternatively you can put these comma-isolated qualities between enclosures moreover. For instance − tup1 = ('material science', 'science', 1997, 2000); tup2 = (1, 2, 3, 4, 5 ); tup3 = "a", "b", "c", "d"; The void tuple is composed as two enclosures containing nothing − tup1 = (); To compose a tuple containing a solitary worth you need to incorporate a comma, despite the fact that there is just one worth − tup1 = (50,); Like string files, tuple records start at 0, and they can be cut, linked, etc. Getting to Values in Tuples To get to values in tuple, u...

Activation functions are a very important component of neural networks in deep learning. It helps us to determine the output of a deep learning model, its accuracy, and also the computational efficiency of training a model. They also have a major effect on how the neural networks will converge and what will be the convergence speed. In some cases, the activation functions might also prevent neural networks from convergence.
So, let’s understand the activation functions, types of activation functions & their importance and limitations in detail.
What is the activation function?
Activation functions help us to determine the output of a neural network. These types of functions are attached to each neuron in the neural network, and determines whether it should be activated or not, based on whether each neuron’s input is relevant for the model’s prediction.
Activation function also helps us to normalize the output of each neuron to a range between 1 and 0 or between -1 and 1.
As we know, sometimes the neural network is trained on millions of data points, So the activation function must be efficient enough that it should be capable of reducing the computation time and improve performance.
Let’s understand how it works?
In a neural network, inputs are fed into the neuron in the input layer. Where each neuron has a weight and multiplying the input number with the weight of each neuron gives the output of the neurons, which is then transferred to the next layer and this process continues. The output can be represented as:
Y = ∑ (weights*input + bias)
Note: The range of Y can be in between -infinity to +infinity. So, to bring the output into our desired prediction or generalized results we have to pass this value from an activation function.
The activation function is a type of mathematical “gate” in between the input feeding the current neuron and its output going to the next layer. It can be as simple as a step function that turns the neuron output on and off, depending on a rule or threshold that is provided. The final output can be represented as shown below:
Y = activation function(summation (weights*input + bias))
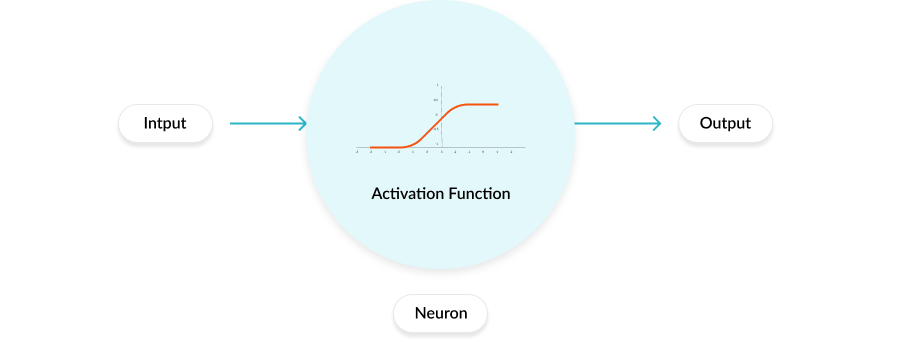
Why we need Activation Functions?
The core idea behind applying any activation functions is to bring non-linearity into our deep learning models. Non-linear functions are those which have a degree more than one, and they have a curvature when we plot them as shown below.
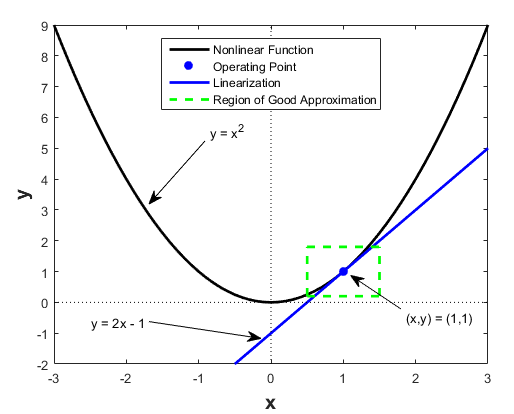
We apply activation function so that we may add the ability to model to learn more complex and complicated data and become more powerful. It also helps to represent non-linear complex arbitrary functional mappings between inputs and outputs. By applying non-linear activation, we are able to bring non-linear mappings between the input and output.
One another important feature of an activation function is that it should be differentiable. We need it to be differentiable because while performing backpropagation optimization strategy while propagating backward in the network to compute gradients of error (loss) with respect to weights and, therefore, optimize weights using gradient descent or any other optimization techniques to reduce the error.
Types of Activation Functions used in Deep Learning
Below mentioned are some of the different type’s activation functions used in deep learning.
1. Binary step
2. Linear
3. Sigmoid
4. Softmax
5. Tanh
6. ReLu
7. LeakyReLU
8. PReLU
9. ELU (Exponential Linear Units)
10. Swish
11. Maxout
12. Softplus
Note: In this article, I will give a brief introduction of the most commonly used activation functions, and later I will try to write a separate article on each type of activation function.
The most commonly used linear and nonlinear activation functions are as follows:
1. Binary step
2. Linear
3. Sigmoid
4. Softmax
5. Tanh
6. ReLU
7. LeakyReLU
1) Binary Step Activation function
This is one of the most basic activation functions available to use and most of the time it comes to our mind whenever we try to bound output. It is basically a threshold base activation function, here we fix some threshold value to decide whether that the neuron should be activated or deactivated.
Mathematically, Binary step activation function can be represented as:
f(x) = 1 if x > 0 else 0 if x < 0
And the graph can be represented as below.
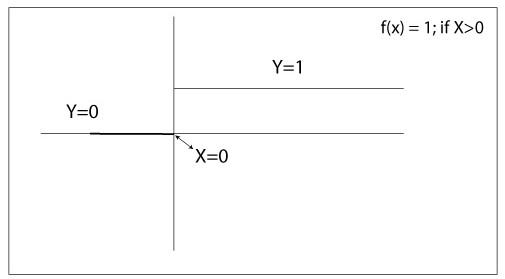
In the above figure, we decided the threshold value to be 0 as shown. The binary Activation function is very simple and useful to use when we want to classify binary problems or classifiers.
One of the problems with the binary step function is that it does not allow multi-value outputs - for example, it does not support classifying the inputs into one of several categories.
2) Linear Activation Functions
The linear activation function is a simple straight-line activation function where the function is directly proportional to the weighted sum of inputs or neurons.
A linear activation function will be in the form as:
Y = mZ
It can be represented in a graph as:
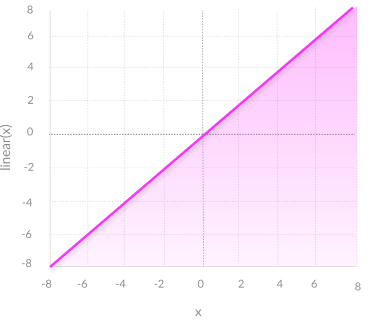
This activation function takes the inputs, multiplies them by the weights of each neuron, and produces the outputs proportional to the input.
Linear activations function is better than a step function because it allows us for multiple outputs instead of only yes or no.
Some of the major problems with Linear Activation problem are as follows:
1. It is not possible to use backpropagation (gradient descent) to train the model as the derivative of this function is constant and has no relationship with the input.
2. With this activation function all layers of the neural network collapse into one.
So, we can simply say that a neural network with a linear activation function is simply a linear regression model. It has limited power and the ability to handle complex problems as varying parameters of input data.
Now, let’s see
Non-Linear Activation Functions
In modern neural network models, it uses non-linear activation functions as the complexity of the model increases. This nonlinear activation function allows the model to create complex mappings between the inputs and outputs of the neural network, which are essential for learning and modeling complex data, such as images, video, audio, and data sets that are non-linear or have very high dimensionality.
With the help of Non-linear functions, we are able to deal with the problems of a linear activation function is:
1. They allow us for backpropagation because they have a derivative function which is having a relationship with the inputs.
2. They also allow us for “stacking” of multiple layers of neurons which helps to create a deep neural network. As we need multiple hidden layers of neurons to learn complex data sets with high levels of accuracy and better results.
3)Sigmoid Activation function
The Sigmoid activation function is one of the most widely used activation function. This function is mostly used as it performs its task with great efficiency. It is basically a probabilistic approach towards decision making and its value ranges between 0 and 1. When we plot this function it is plotted as ‘S’ shaped graph as shown.
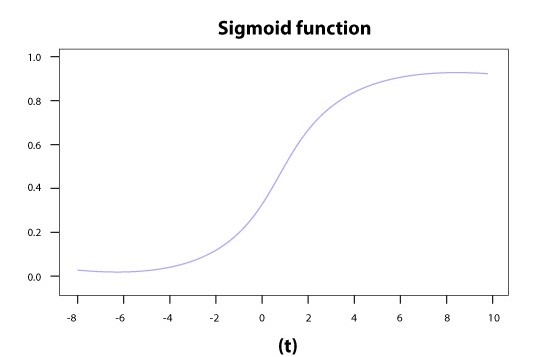
If we have to make a decision or to predict an output, we use this activation function because its range is minimum which helps for accurate prediction.
The equation for the sigmoid function can be given as:
f(x) = 1/(1+e(-x))
Problems with Sigmoid Activation function
The most common issues with the sigmoid function are that it causes a problem mainly in termed of vanishing gradient which occurs because here we converted large input in between the range of 0 to 1 and therefore their derivatives become much smaller which does not give satisfactory output.
Another problem with this activation function is that it is Computationally expensive.
To solve the problem of Sigmoid Activation another activation function such as ReLU is used where we do not have a problem of small derivatives.
4)ReLU (Rectified Linear unit) Activation function
ReLU or Rectified Linear Unit is one of the most widely used activation functions nowadays. It ranges from 0 to Infinity. It is mostly applied in the hidden layers of the Neural network. All the negative values are converted to zero. It produces an output x if x is positive and 0 otherwise.
Equation of this function is:
Y(x) = max(0,x)
The graph of this function is as follows:
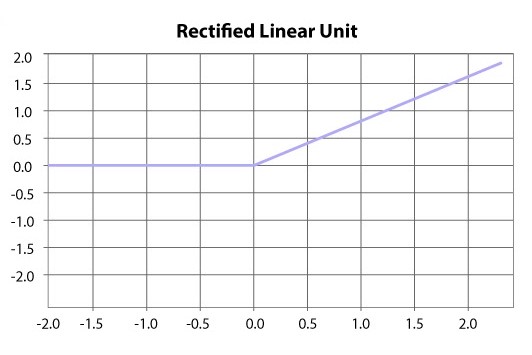
Problems with ReLU activation Function
The Dying ReLU problem: When inputs approach zero or are negative, the gradient of the function becomes zero so the network cannot perform backpropagation and cannot learn properly. This problem is known as The Dying ReLU problem.
So, to avoid this problem we use the Leaky ReLU activation function instead of ReLU. In Leaky ReLU its range is expanded which helps us to enhances the performance of the model.
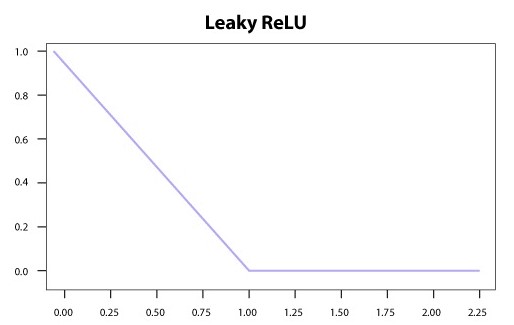
5) Leaky ReLU Activation Function
We needed the Leaky ReLU activation function to solve the ‘Dying ReLU’ problem, as discussed in ReLU. We observe that all the negative input values turn into zero very quickly and in the case of Leaky ReLU we do not make all negative inputs to zero but instead we make a value near to zero which solves the major problem of ReLU activation function and helps us in increasing model performance.
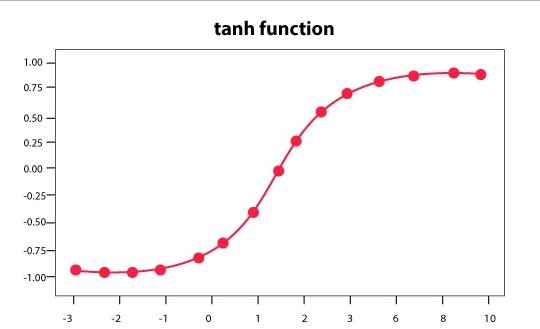
6) Hyperbolic Tangent Activation Function (Tanh)
In most cases, the Tanh activation function always works better than the sigmoid function. Tanh stands for Tangent Hyperbolic function. It’s actually a modified version of the sigmoid function. Both of them can be derived from each other. Its values lie between -1 and 1.
The equation of the tanh activation function is given as:
f(x) = tanh(x) = 2/(1 + e-2x) – 1
OR
tanh(x) = 2 * sigmoid(2x) - 1
The graph of tanh can be shown as:
7) Softmax Activation Function
The Softmax Activation function is also a type of sigmoid function but is quite useful when we are dealing with classification problems. This function is usually used when trying to handle multiple classes.
It would bring the results for each class between 0 and 1 and would also divide by the sum of the outputs.
The softmax function is ideally used in the output layer of the classifier model where we are actually trying to attain the probabilities to define the class of each input.
Note: For Binary classification we can use both sigmoid, as well as the softmax activation function which is equally approachable. But when we are having multi-class classification problems, we generally use softmax and cross-entropy along with it.
The equation of the Softmax Activation function is:
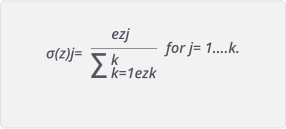
Its graph can be represented as:
As you may get familiar with the most commonly used activation functions. Let me summarize them in one place and provide you a reference as a cheat sheet which you may keep handy whenever you need any reference.

And the graph of different activation functions will look like:

Insideaiml is one of the best platforms where you can learn Python, Data Science, Machine Learning, Artificial Intelligence & showcase your knowledge to the outside world.
Comments
Post a Comment